
2 Saving source and blank slates
2.1 Save source, not the workspace
Think of your R processes as livestock, not pets.
I’m borrowing an analogy used to describe the ethos of cloud computing (history of this meme). Livestock is managed in herds and there is little fuss when individuals are lost or must be sacrificed. A pet, on the other hand, is unique and precious.
Why are individual servers disposable in cloud computing? Because they can be destroyed and replaced at any time and you generally have lots of them. Their creation is automated and the result of the work that they do is recorded in a file or other persistent data store.
I recommend you cultivate a workflow in which you treat R processes (a.k.a. “sessions”) like livestock. Any individual R process and the associated workspace is disposable. Why might this be unappealing? This sounds terrible if your workspace is a pet, i.e. it holds precious objects and you aren’t 100% sure you can reproduce them. This fear is worth designing away, because attachment to your workspace indicates you have a non-reproducible workflow. This is guaranteed to lead to heartache.
Everything that really matters should be achieved through code that you save.
All important objects or figures should be explicitly saved to file, in a granular way. This is in contrast to storing them implicitly or explicitly, as part of an entire workspace, or saving them via the mouse. These recommendations make useful objects readily available for use in other scripts or documents, with the additional assurance that they can be regenerated on-demand. (future link: the API for an analysis)
Saving code – not workspaces – is incredibly important because it is an absolute requirement for reproducibility. Renouncing .Rdata and restarting R often are not intrinsically important or morally superior behaviours. They are important because they provide constant pressure for you to do the right thing: save the source code needed to create all important artefacts of your analysis.
Below we lay out the concrete measures for adopting this workflow.
2.2 Use an IDE
When working with R, save your commands in a .R file, a.k.a. a script, or in .Rmd, a.k.a. an R Markdown document. It doesn’t have to be polished. Just save it!
An integrated development environment (IDE) is critical for making this workflow pleasant. Without an IDE, you edit your code in one app, copy one or more lines to the clipboard, then paste that into R, and execute. Over and over. If this is your life, it is very attractive to type code directly in R!
Any good IDE offers a powerful, R-aware code editor and provides many ways to send your code to a running R process (along with other modern conveniences). This eliminates the temptation to develop code directly in the R Console. Instead, it becomes easier to do the right thing, which is to develop code in a .R or .Rmd file.
Some popular IDEs:
- RStudio: download here or (I recommend) run the Preview version
- Emacs + ESS: https://ess.r-project.org
- vim + Nvim-R: blog post How to Turn Vim Into an IDE for R
- Visual Studio Code: https://code.visualstudio.com/docs/languages/r
Sometimes people resist advice because it’s hard to incorporate into their current workflow and dismiss it as something “for experts only”. But this gets the direction of causality backwards: long-time and professional coders don’t do these things because they use an IDE. They use an IDE because it makes it so much easier to follow best practices.
2.3 Always start R with a blank slate
When you quit R, do not save the workspace to an .Rdata file. When you launch, do not reload the workspace from an .Rdata file.
- In RStudio, set this via Tools > Global Options.
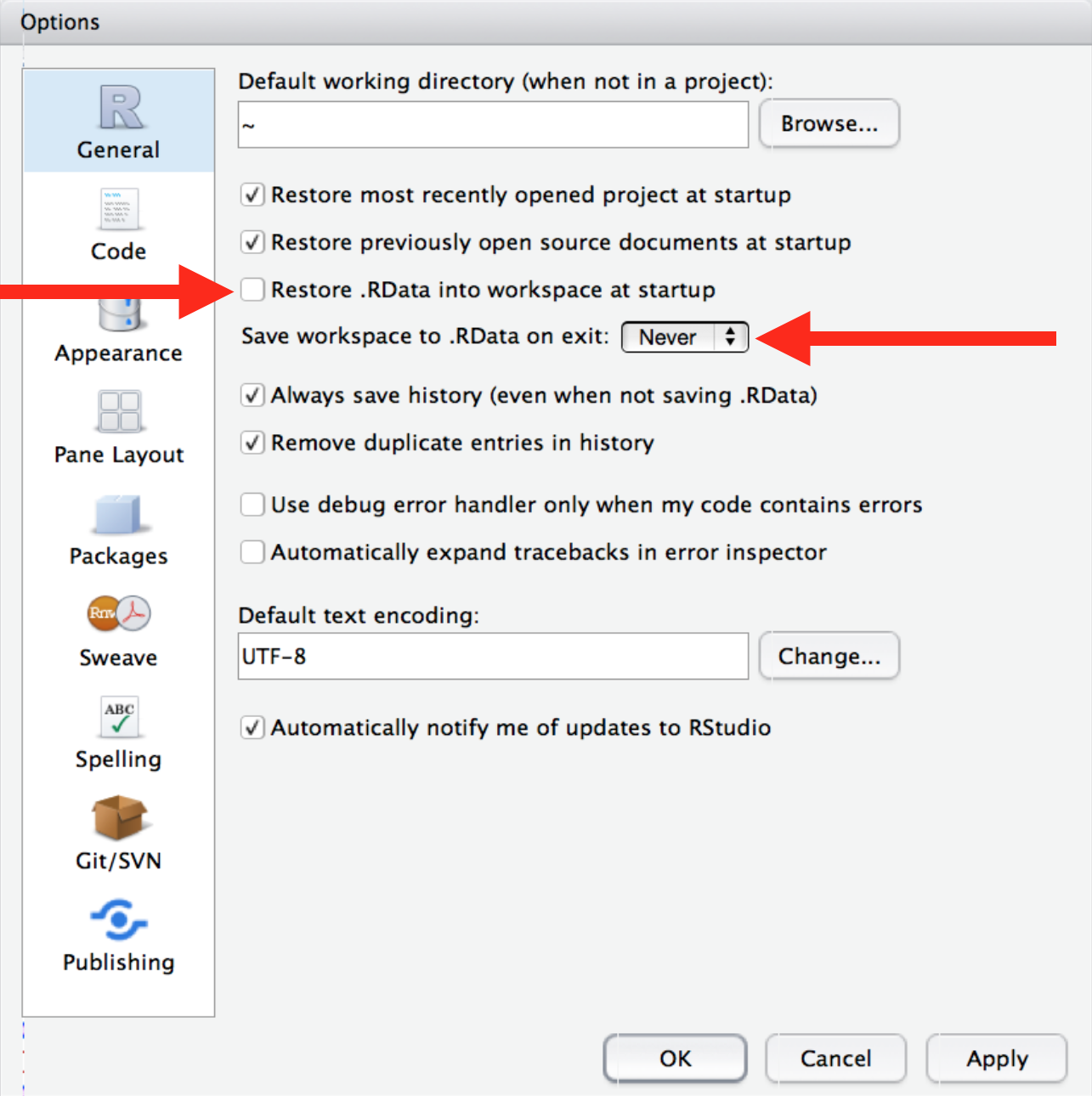
FYI: `usethis::use_blank_slate()` prints a reminder about how to do this.- If you run R from the shell, launch with
R --no-save --no-restore-data. You might want to define an alias in your.bash_profile:alias R='R --no-save --no-restore-data'. Learn more by executingR --helpin a shell.
2.4 Restart R often during development
Have you tried turning it off and then on again?
– timeless troubleshooting wisdom, applies to everything
If you use RStudio, use the menu item Session > Restart R or the associated keyboard shortcut:
- Ctrl+Shift+F10 (Windows and Linux)
- Command+Shift+F10 or Command+Shift+0 (Mac OS)
Additional keyboard shortcuts make it easy to restart development where you left off, i.e. to say “re-run all the code up to HERE”:
- In an R script, use Ctrl+Alt+B (Windows and Linux) or Command+Option+B (Mac OS)
- In R markdown, use Ctrl+Alt+P (Windows and Linux) or Command+Option+P (Mac OS)
If you run R from the shell, use Ctrl+D or q() to quit, then restart R.
2.4.1 Pre-emptively handling a FAQ
No, there is no R command you can put at the top of a script to restart R before executing the rest of the file.
No, this is a not a good reason to build RStudio API hacks into your scripts. We shall not speak of your favorite trick that starts with .rs.api.*.
You use a menu or keyboard shortcut to save your code or to re-indent it or run a spell-checker, right? This is how you should approach restarting R periodically during the day. It’s a workflow task. It does not belong in your code.
Which brings us to …
2.5 What’s wrong with rm(list = ls())?
It’s fairly common to see data analysis scripts that begin with this object-nuking command:
rm(list = ls())This is highly suggestive of a non-reproducible workflow.
This line is meant to reset things, either to power-cycle the current analysis or to switch from one project to another. But there are better ways to do both:
- To power-cycle the current analysis, restart R! See above.
- To switch from one project to another, either restart R or, even better, use an IDE with proper support for projects, where each project gets its own R process. See Project-oriented workflow.
The problem with rm(list = ls()) is that, given the intent, it does not go far enough. All it does is delete user-created objects from the global workspace.
Many other changes to the R landscape persist invisibly and can have profound effects on subsequent development. Any packages that have ever been attached via library() are still available. Any options that have been set to non-default values remain that way. Working directory is not affected (which is, of course, why we see setwd() so often here too!).
Why does this matter? It makes your script vulnerable to hidden dependencies on things you ran in this R process before you executed rm(list = ls()).
- You might use functions from a package without including the necessary
library()call. Your collaborator won’t be able to run this script. - You might code up an analysis assuming that
stringsAsFactors = FALSEbut next week, when you have restarted R, everything will inexplicably be broken. - You might write paths relative to some random working directory, then be puzzled next month when nothing can be found or results don’t appear where you expect.
The solution is to write every script assuming it will be run in a fresh R process. The best way to do that is … develop scripts in a fresh R process!
There is nothing inherently evil about rm(list = ls()). It’s a red flag, because it is indicative of a non-reproducible workflow. Since it appears to “work” ~90% of the time, it’s very easy to deceive yourself into thinking your script is self-contained, when it is not.
2.6 Objects that take a long time to create
Power-cycling your analysis regularly can be very painful if there are parts that take a long time to execute.
This indicates it’s time for a modular approach that breaks the analysis into natural phases, each with an associated script and outputs. (future link: API for an analysis) Isolate each computationally demanding step in its own script and write the precious object to file with saveRDS(my_precious, here("results", "my_precious.rds")). Now you can develop scripts to do downstream work that reload the precious object via my_precious <- readRDS(here("results", "my_precious.rds")). Breaking an analysis into logical steps, with clear inputs and outputs, is a good idea anyway.
2.7 Automated workflows
Various approaches exist for automating a workflow, i.e. running a set of scripts in sequence. Many people can get by with low-tech solutions, such as using GNU Make or even writing a pseudo-Makefile in R.
If you use one “controller” script to run other R scripts or to render multiple R Markdown documents, it’s a good idea to force the use of a fresh R process for each one. If your controller script is written in R, consider using the callr package to source() or render() each worker script or .Rmd in its own R session.
The R package targets is gaining traction as a formal tool for workflow automation (sort of GNU make, but for R):
targets skips costly runtime for tasks that are already up to date, [and] orchestrates the necessary computation with implicit parallel computing…
2.8 Links to other resources
This page from STAT 545 covers some of the same ground, but aimed at someone quite new to R.
The post Project-oriented workflow from the tidyverse blog is an earlier effort to explain why rm(list = ls()) and setwd() indicate a sub-optimal workflow.
- That lead to a lively thread on community.rstudio.com where lots of useRs share their experience and tricks.